Getting Started with Web Scraping Using Golang and Scrapemate
I am a software engineer based in Cyprus with over 20 years of experience in the industry. My background in Computer Science has led me to work with PHP, Python, and more recently, with a focus on Golang.
Originally from Greece, my career has taken me across Europe, and I now call Cyprus home. I've attended numerous conferences, continually expanding my knowledge and network.
Recently, I started blogging to share my insights and experiences with the tech community. I'm passionate about engaging with fellow developers and contributing to the field through my writing and future projects.
Thank you for visiting my blog.
Introduction
Web scraping is the process of extracting data from websites, and it can be a powerful tool for collecting information for research, analysis, or automation.
In this tutorial, I will show you how to use Golang and the Scrapemate framework to scrape data from a website.
As an example, we will extract product information from https://scrapeme.live/shop/. Specifically, we'll extract
title
price
short_description
sku
categories
for each of the Pokemon products on the site.
Once we have this data, we'll create a CSV file containing it.
See the image below with highlighted the data we need to extract for each product
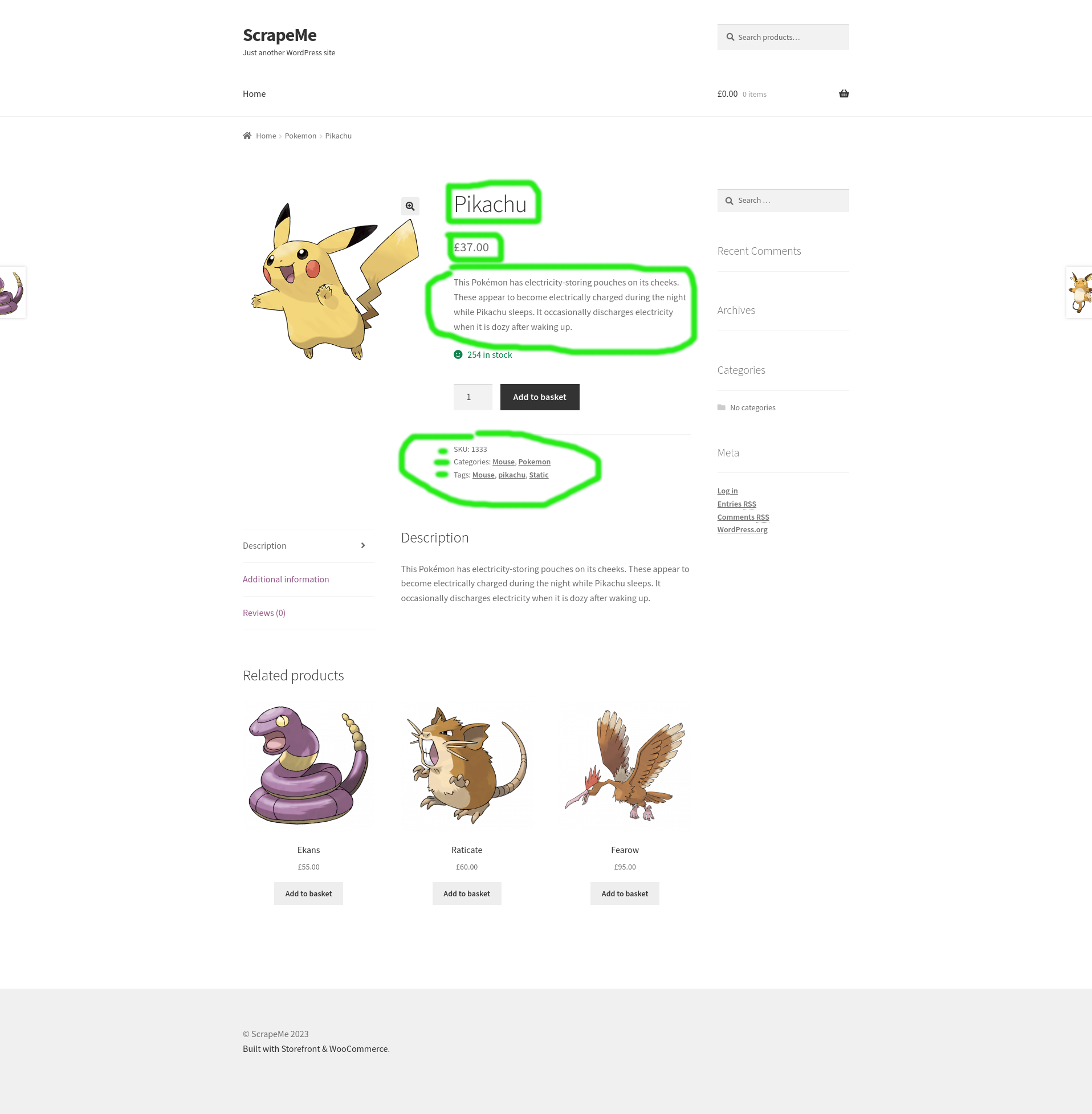
Prerequisites
Before you get started make sure that you have a Golang version >=1.20 installed. You can find installation instructions here
Step1: Inspecting the website
The first step in any web scraping project is to inspect the website you want to scrape. In our case, we want to extract data about Pokemon products from https://scrapeme.live/shop/.
Finding the css-selectors from the home page
Open https://scrapeme.live/shop/ in your browser. This opens the home page of the Pokemon e-shop.
This will be the starting page for our scraper.
Our scraper should try to find all the links to the products (pokemon in that case) and additionally, it should find the link to the next page.
The idea is that we should visit all the pages via pagination and for each page we extract the Pokemon product links. We also visit them and extract the information.
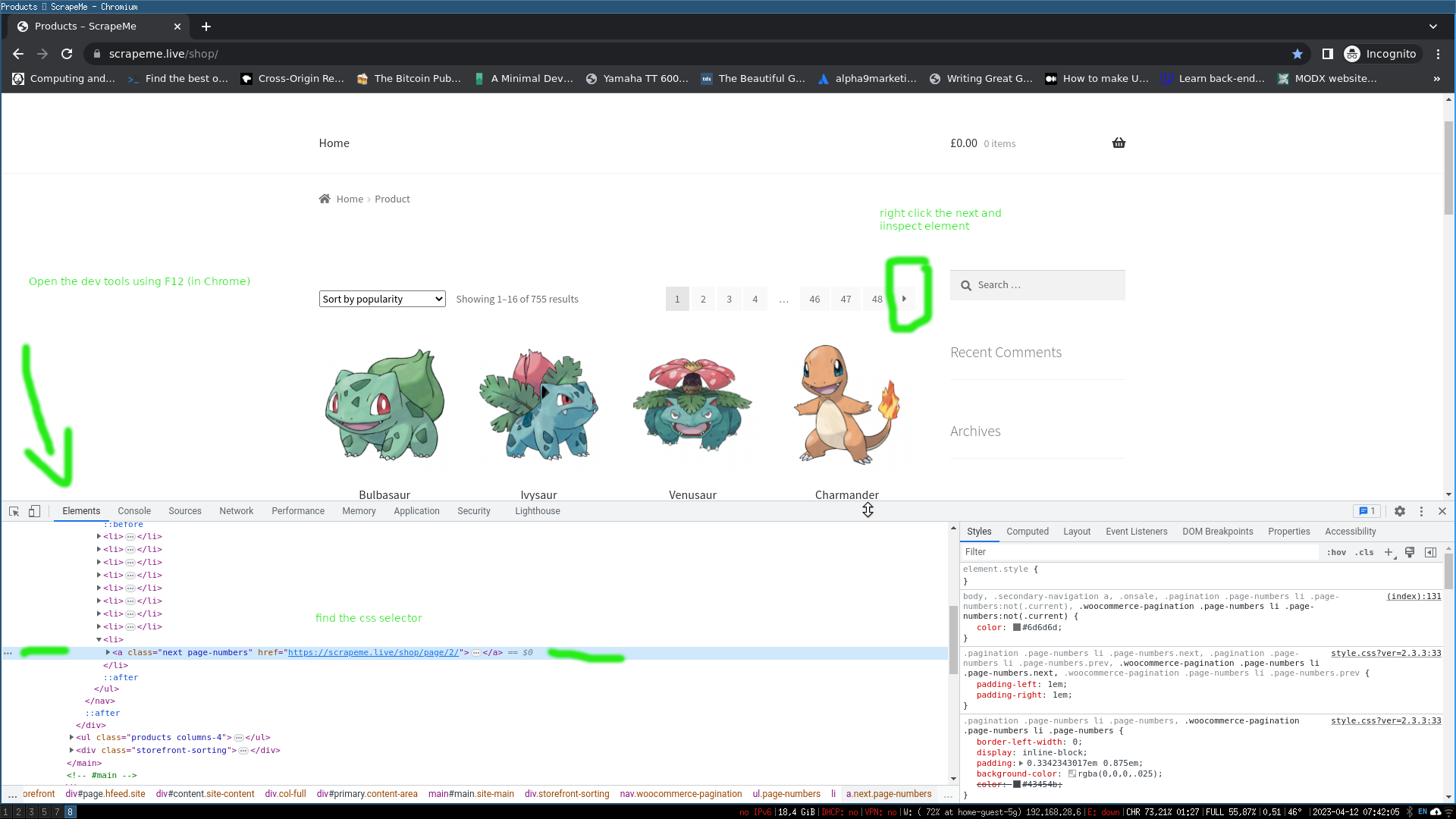
By using Chrome's Developer tools and by right-clicking the element we are interested in we can find a suitable CSS selector so we can extract the information in our parser.
In the image above I show you how can you do it in Chrome:
Hit F12 to open developer tools
Right click the
nextarrow that takes you to the next page and click inspect elementthen in the developer's tools you can find the proper CSS selector
In our case to get the page to the next link we need to use the element
with the following CSS selector:
a.next.page-numbers
By right-clicking on a product (pokemon) image we can inspect the element and find the element that contains that lint that takes us to the detailed product page.
In our case it's
a.woocommerce-LoopProduct-link
finding the CSS selectors for the product details page
Now visit a product detail page like https://scrapeme.live/shop/Bulbasaur/
Similarly, we find the CSS selectors for the elements we are interested in.
In particular, we have:
title :
h1.product_titleprice:
p.priceshort_description:
div.woocommerce-product-details__short-description>psku:
span.skucategories:
div.product_meta > span.posted_in > atags:
div.product_meta > span.tagged_as > a
Step2: Create project skeleton
You need to create a folder that will host your code:
mkdir scrapemelive
cd scrapemelive
initialize a go module using go mod init
go mod init scrapemelive
Then create the following folders:
mkdir scrapemelive
mkdir testdata
the contents of the folder should be:
├── go.mod
├── scrapemelive
└── testdata
Add also a main.go file which just prints 'hello world' for the moment.
touch main.go
open main.go into your editor and add the following:
package main
import "fmt"
func main() {
fmt.Println("hello world")
}
Let's test that the code can run by running go run main.go .
You should see in the standard output the hello world printed.
The main.go file will contain the code that will start our scraper and the code that writes the results to CSV.
The folder scrapemelive will contain the necessary functions/types/code that the framework will use
The folder testdata will contain data that we need for our unit tests.
Step 3: Writing the Scraping Code
Let's first create a file in scrapemelive/product.go . Here we are going to add a struct that holds the Product data that we scrape.
package scrapemelive
// Product is a product scraped from the detail page
type Product struct {
// Name is the name of the product
Title string
// Price is the price of the product
Price string
// ShortDescription is the short description of the product
ShortDescription string
// Sku is the sku of the product
Sku string
// Categories is the categories of the product
Categories []string
// Tags is the tags of the product
Tags []string
}
Each scraped Product will be an instance of the Product struct.
Let's also create a scrapemelive/product_test.go file in which we will write our unit tests. For now, it will be empty
package scrapemelive
Our project folder should look like this
├── go.mod
├── main.go
├── scrapemelive
│ ├── product.go
│ └── product_test.go
└── testdata
The next step is to write the functions that extract the data from the detail page based on the css selectors we identified above.
Open the scrapemelive/product.go file and add the following
func parseTitle(doc *goquery.Document) string {
return doc.Find("h1.product_title").Text()
}
func parsePrice(doc *goquery.Document) string {
return doc.Find("p.price").Text()
}
func parseShortDescription(doc *goquery.Document) string {
return doc.Find("div.woocommerce-product-details__short-description>p").Text()
}
func parseSku(doc *goquery.Document) string {
return doc.Find("span.sku").Text()
}
func parseCategories(doc *goquery.Document) []string {
var categories []string
doc.Find("div.product_meta > span.posted_in > a").Each(func(i int, s *goquery.Selection) {
categories = append(categories, s.Text())
})
return categories
}
func parseTags(doc *goquery.Document) []string {
var tags []string
doc.Find("div.product_meta > span.tagged_as > a").Each(func(i int, s *goquery.Selection) {
tags = append(tags, s.Text())
})
return tags
}
We need the goquery library so let's also get it
go get github.com/PuerkitoBio/goquery
make sure you also import at the top of the file the import for goquery
import "github.com/PuerkitoBio/goquery"
Each of the above functions accepts a *goquery.Document as an input, extracts from the document the data we are interested using goquery in and returns them.
We wrote some code but it's not tested yet. Let's write some tests then.
Before writing the tests let's download the HTML of a product page in our test data directory:
curl -o testdata/sample-product.html 'https://scrapeme.live/shop/Charmeleon/'
The command above saves the HTML for the Charmeleon product in the file testdata/sample-product.html.
Let's now add some tests.
For unit tests we use the testify library, so get it via go get
go get github.com/stretchr/testify/require
In scrapemelive/product_test.go add the following:
package scrapemelive
import (
"os"
"testing"
"github.com/PuerkitoBio/goquery"
"github.com/stretchr/testify/require"
)
func openTestFile(t *testing.T, filename string) *goquery.Document {
t.Helper()
file, err := os.Open(filename)
require.NoError(t, err)
defer file.Close()
doc, err := goquery.NewDocumentFromReader(file)
require.NoError(t, err)
return doc
}
func Test_parseTitle(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-product.html")
require.Equal(t, "Charmeleon", parseTitle(doc))
}
func Test_parsePrice(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-product.html")
require.Equal(t, "£165.00", parsePrice(doc))
}
func Test_parseShortDescription(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-product.html")
require.Equal(t, "Charmeleon mercilessly destroys its foes using its sharp claws. If it encounters a strong foe, it turns aggressive. In this excited state, the flame at the tip of its tail flares with a bluish white color.", parseShortDescription(doc))
}
func Test_parseSku(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-product.html")
require.Equal(t, "6565", parseSku(doc))
}
func Test_parseCategories(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-product.html")
require.ElementsMatch(t, []string{"Pokemon", "Flame"}, parseCategories(doc))
}
func Test_parseTags(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-product.html")
require.ElementsMatch(t, []string{"Blaze", "charmeleon", "Flame"}, parseTags(doc))
Let's run our tests:
go test -v ./...
All tests must pass like:
? scrapemelive [no test files]
=== RUN Test_parseTitle
=== PAUSE Test_parseTitle
=== RUN Test_parsePrice
=== PAUSE Test_parsePrice
=== RUN Test_parseShortDescription
=== PAUSE Test_parseShortDescription
=== RUN Test_parseSku
=== PAUSE Test_parseSku
=== RUN Test_parseCategories
=== PAUSE Test_parseCategories
=== RUN Test_parseTags
=== PAUSE Test_parseTags
=== CONT Test_parseTitle
=== CONT Test_parseSku
=== CONT Test_parseShortDescription
=== CONT Test_parsePrice
=== CONT Test_parseTags
=== CONT Test_parseCategories
--- PASS: Test_parseShortDescription (0.00s)
--- PASS: Test_parseTitle (0.00s)
--- PASS: Test_parseSku (0.00s)
--- PASS: Test_parsePrice (0.00s)
--- PASS: Test_parseCategories (0.00s)
--- PASS: Test_parseTags (0.00s)
PASS
ok scrapemelive/scrapemelive 0.005s
This verifies that our parsing functions work as we expect.
The next step is to add a function product.go that uses all these functions and returns a Product .
In scrapemelive/product.go add the following function:
func parseProduct(doc *goquery.Document) Product {
return Product{
Title: parseTitle(doc),
Price: parsePrice(doc),
ShortDescription: parseShortDescription(doc),
Sku: parseSku(doc),
Categories: parseCategories(doc),
Tags: parseTags(doc),
}
}
Don't forget to add a unit test in scrapemelive/product_test.go also for this function
func Test_parseProduct(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-product.html")
product := parseProduct(doc)
require.Equal(t, "Charmeleon", product.Title)
require.Equal(t, "£165.00", product.Price)
require.Equal(t, "Charmeleon mercilessly destroys its foes using its sharp claws. If it encounters a strong foe, it turns aggressive. In this excited state, the flame at the tip of its tail flares with a bluish white color.", product.ShortDescription)
require.Equal(t, "6565", product.Sku)
require.ElementsMatch(t, []string{"Pokemon", "Flame"}, product.Categories)
require.ElementsMatch(t, []string{"Blaze", "charmeleon", "Flame"}, product.Tags)
}
Make sure your tests still pass by running go test -v ./... .
(Scrapemate)[https://github.com/gosom/scrapemate] accepts jobs that implement a specific interface scrapemate.IJob . Luckily, there is an implementation of that interface that we can use as a base (scrapemate.Job) .
We previously identified that we have two types of pages:
the listing pages, which contain multiple products and pagination. An example of a listing page is: https://scrapeme.live/shop/
the product or detail page, which contains the data for a specific product. An example of a detail page is: https://scrapeme.live/shop/Charmeleon/
IJob interface has a method with the following signature:
Process(ctx context.Context, resp scrapemate.Response) (any, []scrapemate.IJob, error)
It accepts:
context.Context: which is a context object
scrapemate.Response: the Response object that contains thegoquery.Documentand other fields.
it returns:
any: this is the result of the scraper
[]scrapemate.IJob: when we parse a web page we may need to instruct the scraper to visit other pages that we have discovered. So we return the next pages to visit there.
error: returns an error if there is one
Based on the above and in particular to the []scrapemate.IJob explanation we understand that we need two types of jobs.
ProductCollectJob: for the listing pages
ProductJob: for the product detail pages
The ProductCollectJob will extract the next page link and create another ProductCollectJob and will extract the product details and other ProductJob.
The ProductJob is responsible to return a Product and it does not have other jobs to return.
Install some dependencies:
go get github.com/gosom/scrapemate
go get github.com/gosom/kit/logging
go get github.com/google/uuid
ProductJob
Let's create first the ProductJob by creating a file scrapemelive/detail.go .
package scrapemelive
import (
"context"
"errors"
"github.com/PuerkitoBio/goquery"
"github.com/gosom/kit/logging"
"github.com/gosom/scrapemate"
)
type ProductJob struct {
scrapemate.Job
}
func (o *ProductJob) Process(ctx context.Context, resp *scrapemate.Response) (any, []scrapemate.IJob, error) {
log := ctx.Value("log").(logging.Logger)
log.Info("processing product job")
doc, ok := resp.Document.(*goquery.Document)
if !ok {
return nil, nil, errors.New("failed to convert response to goquery document")
}
product := parseProduct(doc)
return product, nil, nil
}
Let's explain a bit about what the above is doing:
We create a new struct called ProductJob in which we embed the scrapemate.Job and we implement the method Process to accommodate our needs.
The Process method for that job has to parse the document fetched and extract the data we need and create an instance of Product. We then need to return that newly scraped Product.
We explain a bit more almost line by line:
Scrapemate offers you a logger and you can get it from context via
ctx.Value("log").(logging.Logger)
In order to fetch the document we need to do:
doc, ok := resp.Document.(*goquery.Document)
Notice the typecasting, this is because scrapemate gives you the capability to configure the type of document parser you want to use. We will see that when we initialize the framework.
Once we have a document we can extract the information we need and create a product.
product := parseProduct(doc)
Notice, that this is the function we created before, nothing more to explain here.
Finally, we return
return product, nil, nil
The order of return is :
first: the data we parsed, here the
productsecond: the next jobs that the scraper should process - here nothing
third: an error if there is any - here no error
ProductCollectJob
The ProductCollectJob will extract the required links (for products and for the next page) and will return new jobs.
create the file scrapemelive/collect.go and add the following contents
package scrapemelive
import (
"context"
"errors"
"time"
"github.com/PuerkitoBio/goquery"
"github.com/google/uuid"
"github.com/gosom/kit/logging"
"github.com/gosom/scrapemate"
)
type ProductCollectJob struct {
scrapemate.Job
}
func (o *ProductCollectJob) Process(ctx context.Context, resp *scrapemate.Response) (any, []scrapemate.IJob, error) {
log := ctx.Value("log").(logging.Logger)
log.Info("processing collect job")
doc, ok := resp.Document.(*goquery.Document)
if !ok {
return nil, nil, errors.New("failed to convert response to goquery document")
}
var nextJobs []scrapemate.IJob
links := parseProductLinks(doc)
for _, link := range links {
nextJobs = append(nextJobs, &ProductJob{
Job: scrapemate.Job{
ID: uuid.New().String(),
Method: "GET",
URL: link,
Headers: map[string]string{
"User-Agent": scrapemate.DefaultUserAgent,
},
Timeout: 10 * time.Second,
MaxRetries: 3,
Priority: 0,
},
})
}
nextPage := parseNextPage(doc)
if nextPage != "" {
nextJobs = append(nextJobs, &ProductCollectJob{
Job: scrapemate.Job{
ID: uuid.New().String(),
Method: "GET",
URL: nextPage,
Headers: map[string]string{
"User-Agent": scrapemate.DefaultUserAgent,
},
Timeout: 10 * time.Second,
MaxRetries: 3,
Priority: 1,
},
})
}
return nil, nextJobs, nil
}
func parseProductLinks(doc *goquery.Document) []string {
var links []string
doc.Find("a.woocommerce-LoopProduct-link").Each(func(i int, s *goquery.Selection) {
link, _ := s.Attr("href")
links = append(links, link)
})
return links
}
func parseNextPage(doc *goquery.Document) string {
return doc.Find("a.next.page-numbers").AttrOr("href", "")
}
Notice here that we have at the end of the file two functions
parseProductLinksparseNextPage
They do what the name implies.
First, it extracts all the links for the products and returns a slice of strings that contains the links.
The second function extracts the links that take us to the next page in the pagination.
Let's see in more detail the Process method
var nextJobs []scrapemate.IJob
links := parseProductLinks(doc)
for _, link := range links {
nextJobs = append(nextJobs, &ProductJob{
Job: scrapemate.Job{
ID: uuid.New().String(),
Method: "GET",
URL: link,
Headers: map[string]string{
"User-Agent": scrapemate.DefaultUserAgent,
},
Timeout: 10 * time.Second,
MaxRetries: 3,
Priority: 0,
},
})
}
The portion of the code above is responsible to :
parse the links out of the webpage
create a ProductJob for each link and append it to
nextJobsslice
nextPage := parseNextPage(doc)
if nextPage != "" {
nextJobs = append(nextJobs, &ProductCollectJob{
Job: scrapemate.Job{
ID: uuid.New().String(),
Method: "GET",
URL: nextPage,
Headers: map[string]string{
"User-Agent": scrapemate.DefaultUserAgent,
},
Timeout: 10 * time.Second,
MaxRetries: 3,
Priority: 1,
},
What we do here is that we first parse the next link.
Afterward, if the next link is not empty we create a ProductCollectJob and we append it to the nextJobs slice.
Let's write some tests for the parseProductLinks and parseNextPage functions.
Fetch a listing page and store its HTML to testdata folder
curl -o testdata/sample-category.html 'https://scrapeme.live/shop/'
Create a file scrapemelive/collect_test.go and add:
package scrapemelive
import (
"testing"
"github.com/stretchr/testify/require"
)
func Test_parseProductLinks(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-category.html")
links := parseProductLinks(doc)
require.Len(t, links, 16)
}
func Test_parseNextPage(t *testing.T) {
t.Parallel()
doc := openTestFile(t, "../testdata/sample-category.html")
nextPage := parseNextPage(doc)
require.Equal(t, "https://scrapeme.live/shop/page/2/", nextPage)
}
Make sure tests pass:
go test -v ./...
Main function
Now it's time to write our main.go function.
Instal another dependency
go get github.com/gosom/scrapemate/adapters/cache/leveldbcache
Now in your main.go add the following
package main
import (
"context"
"errors"
"net/http"
"os"
"time"
"github.com/google/uuid"
"github.com/gosom/scrapemate"
"github.com/gosom/scrapemate/adapters/cache/leveldbcache"
fetcher "github.com/gosom/scrapemate/adapters/fetchers/nethttp"
parser "github.com/gosom/scrapemate/adapters/parsers/goqueryparser"
provider "github.com/gosom/scrapemate/adapters/providers/memory"
"scrapemelive/scrapemelive"
)
func main() {
err := run()
if err == nil || errors.Is(err, scrapemate.ErrorExitSignal) {
os.Exit(0)
return
}
os.Exit(1)
}
func run() error {
ctx, cancel := context.WithCancelCause(context.Background())
defer cancel(errors.New("deferred cancel"))
provider := provider.New()
go func() {
job := &scrapemelive.ProductCollectJob{
Job: scrapemate.Job{
ID: uuid.New().String(),
Method: http.MethodGet,
URL: "https://scrapeme.live/shop/",
Headers: map[string]string{
"User-Agent": scrapemate.DefaultUserAgent,
},
Timeout: 10 * time.Second,
MaxRetries: 3,
},
}
provider.Push(ctx, job)
}()
httpFetcher := fetcher.New(&http.Client{
Timeout: 10 * time.Second,
})
cacher, err := leveldbcache.NewLevelDBCache("__leveldb_cache")
if err != nil {
return err
}
mate, err := scrapemate.New(
scrapemate.WithContext(ctx, cancel),
scrapemate.WithJobProvider(provider),
scrapemate.WithHTTPFetcher(httpFetcher),
scrapemate.WithConcurrency(10),
scrapemate.WithHTMLParser(parser.New()),
scrapemate.WithCache(cacher),
)
if err != nil {
return err
}
resultsDone := make(chan struct{})
go func() {
defer close(resultsDone)
if err := writeCsv(mate.Results()); err != nil {
cancel(err)
return
}
}()
err = mate.Start()
<-resultsDone
return err
}
func writeCsv(results <-chan scrapemate.Result) error {
// TODO
return nil
}
Let's go over it slowly:
Initially, the function run is called and it returns an error.
scrapemate returns a special error ErrorExitSignal when the program exits because it captured a SIGINT. In such a case we want it to exist with status code 0.
In the other cases, we return exit code 1.
Now, the run function. A lot is happening here
Scrapemate requires as to first declare a job provider:
provider := provider.New()
go func() {
job := &scrapemelive.ProductCollectJob{
Job: scrapemate.Job{
ID: uuid.New().String(),
Method: http.MethodGet,
URL: "https://scrapeme.live/shop/",
Headers: map[string]string{
"User-Agent": scrapemate.DefaultUserAgent,
},
Timeout: 10 * time.Second,
MaxRetries: 3,
},
}
provider.Push(ctx, job)
}()
A provider is a data structure that provides jobs to the scraper. Here we want to start our crawler with the homepage of the e-shop. We create the initial job and we push to the provider.
We also have to define how we are going to fetch webpages. For this purpose, we need an instance of a fetcher
httpFetcher := fetcher.New(&http.Client{
Timeout: 10 * time.Second,
})
We also want to cache the responses so we initialize an instance of a Cacher.
cacher, err := leveldbcache.NewLevelDBCache("__leveldb_cache")
if err != nil {
return err
}
Above, we are going to cache using leveldb and the database will be created in a folder named __leveldb_cache .
We can now initialize our scraper:
mate, err := scrapemate.New(
scrapemate.WithContext(ctx, cancel),
scrapemate.WithJobProvider(provider),
scrapemate.WithHTTPFetcher(httpFetcher),
scrapemate.WithConcurrency(10),
scrapemate.WithHTMLParser(parser.New()),
scrapemate.WithCache(cacher),
)
if err != nil {
return err
}
Notice the WithConcurrency , this configures the framework to use 10 parallel workers.
The WithHtml parser configures the html parser. We chose to use the default one, which uses goquery.
scrapemate.WithHtmlParser(parser.New()),
Once Scrapemate finishes a job it pushes the result into a channel. To acces that channel we can use the mate.Results() method.
resultsDone := make(chan struct{})
go func() {
defer close(resultsDone)
if err := writeCsv(mate.Results()); err != nil {
cancel(err)
return
}
}()
The above snippet starts a new goroutine that is responsible to write the results in a CSV file.
In the last part
err = mate.Start()
<-resultsDone
return err
we just start the scraper and wait until all the results are written.
The scraper, even if it has no more jobs will still wait until you kill it via ctrl-c.
CSV writing
In our task description, we want to create a CSV with headers:
title,price,short_description,sku,categories,tags
Open scrapemelive.go and add the following:
func (o Product) CsvHeaders() []string {
return []string{
"title",
"price",
"short_description",
"sku",
"categories",
"tags",
}
}
func (o Product) CsvRow() []string {
return []string{
o.Title,
o.Price,
o.ShortDescription,
o.Sku,
strings.Join(o.Categories, ","),
strings.Join(o.Tags, ","),
}
}
Now open main.go and replace the function writeCsv with the following:
func writeCsv(results <-chan scrapemate.Result) error {
w := csv.NewWriter(os.Stdout)
defer w.Flush()
headersWritten := false
for result := range results {
if result.Data == nil {
continue
}
product, ok := result.Data.(scrapemelive.Product)
if !ok {
return fmt.Errorf("unexpected data type: %T", result.Data)
}
if !headersWritten {
if err := w.Write(product.CsvHeaders()); err != nil {
return err
}
headersWritten = true
}
if err := w.Write(product.CsvRow()); err != nil {
return err
}
w.Flush()
}
return w.Error()
}
The code above just takes each result from the Results channel and writes it to the CSV file.
Run the scraper
Now that all the code is in place we can run our scraper.
go run main.go 1>pokemons.csv
This will take some time. Meanwhile, you will see the logs in your screen.
Once the logs stop updating wait a few seconds and hit CTRL-C.
{"level":"info","component":"scrapemate","job":"Job{ID: 4de24748-1e8e-4ab7-843f-8571ca8b2d49, Method: GET, URL: https://scrapeme.live/shop/Blacephalon/, UrlParams: map[]}","status":"success","duration":1323.897329,"time":"2023-04-14T07:41:41.911948749Z","message":"job finished"}
^C{"level":"info","component":"scrapemate","time":"2023-04-14T07:42:13.345446924Z","message":"received signal, shutting down"}
{"level":"info","component":"scrapemate","time":"2023-04-14T07:42:13.345757168Z","message":"scrapemate exited"}
You should see something like the above.
The results should be in pokemons.csv file.
Summary
In this tutorial, I have shown how to use Golang and Scrapemate to extract data from a website.
Specifically, I demonstrated how to scrape product information from the website https://scrapeme.live/shop/ by extracting the title, price, short_description, sku, tags, and categories for each of the Pokemon products on the site.
I used Scrapemate, a Golang-based scraping framework, to perform the web scraping, and then wrote the scraped data to a CSV file.
This example illustrates how web scraping can be a powerful tool for collecting information for research, analysis, or automation, and how Scrapemate can simplify the process of building scraping tools in Golang.
You can find all the code above in github



